Roxana Virlan, Denisa Gal
Introduction
"Reasoning is the process of drawing logical conclusions from given
information. It is a key component of AI applications such as expert
systems, natural language processing and machine learning. It allows
computers to draw logical conclusions from data and knowledge, and
to make decisions based on those conclusions." [1]
ViperGPT [2] and VisProg [3] are just two of the newest reasoning based
frameworks that emerged in the vast field that is machine learning.
ViperGPT
ViperGPT [2] is a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. It utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.


So how exactly does it work? It creates customized programs for each query that take images or videos as arguments and return the result of the query for that image or video. Given a visual input x and a textual query q about its contents, the authors first synthesize a program z=π(q) with a program generator π given the query. After that, the execution engine r=ϕ(x,z) is applied to execute the program z on the input x and produce a result r. This framework is flexible, supporting image or videos as inputs x, questions or descriptions as queries q, and any type (e.g., text or image crops) as outputs r.
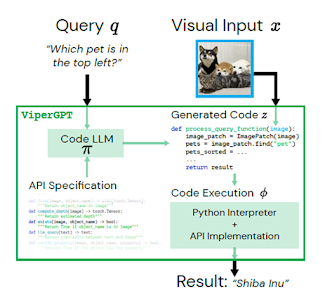
The model’s prior training on code enables it to reason about how to use these functions and implement the relevant logic. Benefits of this approach:
interpretable, as all the steps are explicit as code function calls with intermediate values that can be inspected;
logical, as it explicitly uses built-in Python logical and mathematical
operators;
flexible, as it can easily incorporate any vision or language module, only requiring the specification of the associated module be added to the API;
compositional, decomposing tasks into smaller sub-tasks performed step by-step;
adaptable to advances in the field, as improvements in any of the used modules will result in a direct improvement in our approach’s performance;
training-free, as it does not require to re-train (or finetune) a new model for every new task;
general, as it unifies all tasks into one system.
Different evaluation settings to showcase the model’s diverse capabilities in varied contexts without additional training: visual grounding, compositional image question answering, external knowledge-dependent image question answering, video causal and temporal reasoning.
Visual grounding is the task of identifying the bounding box in an image that corresponds best to a given natural language query. Visual grounding tasks evaluate reasoning about spatial relationships and visual attributes. For evaluation, the RefCOCO and RefCOCO+ Datasets were used (TABLE 1).


Compositional Image Quotation Answering: they also evaluate ViperGPT on image question answering (focus on compositional question answering, which requires decomposing complex questions into simpler tasks). GQA dataset was used, which was created to measure performance on complex compositional questions. (TABLE 2)


External Knowledge dependent Image Question Answering: by equipping ViperGPT with a module to query external knowledge bases in natural language, it can combine knowledge with visual reasoning to handle such questions. They evaluate on the OK-VQA dataset, which is designed to evaluate models’ ability to answer questions about images that require knowledge that cannot be found in the image (TABLE 3).


Video Causal/Temporal Reasoning: they also evaluate how ViperGPT extends to videos and queries that require causal and temporal reasoning. To explore this, they use the NExT-QA dataset, designed to evaluate video models ability to perform this type of reasoning.


ViperGPT is a framework for programmatic composition of specialized vision, language, math, and logic functions for complex visual queries. ViperGPT is capable of connecting individual advances in vision and language; it enables them to show capabilities beyond what any individual model can do on its own.
VisProg
VISPROG [3] is a neuro-symbolic approach that takes natural language instructions and solves complex and compositional visual tasks. It avoids the need for task-specific training, using the in-context learning ability of LLM (large language models) to generate python-like modular programs, which are then executed to get both the solution and a comprehensive and interpretable rationale.
It takes as inputs visual data (a single image or a set of images) along with a natural language instruction and generates a sequence of steps (visual program) then executes them to produce the desired output.

Each step invokes one of the modules of the system. Each module is implemented as a python class, with methods for parsing, executing and summarizing (visual rationale). There are currently 20 modules for enabling capabilities such as:
image understanding
image manipulation (including generation)
knowledge retrieval
performing logical and arithmetic operations

VISPROG prompts GPT-3 with pairs of instructions and the desired high-level program, making use of its in-context learning ability, resulting in visual programs for natural language instructions. Each line of the program consists of the name of a module, the input argument names for the module and their values, and an output variable name (Figure 3). The resulting program can be executed on the input image in order to obtain the desired effect. This execution is handled by the interpreter.

The interpreter initializes the program state with the inputs, and steps through the program line-by-line while invoking the correct module with the inputs specified in that line. After executing each step, the outputs of the previous state become the inputs for the new one.

Additionally, each module class produces a HTML snippet to visually summarize the inputs and outputs of the module. The snippets of all steps are then stitched by the interpreter into a visual rationale (Figure 4).
This can be used to analyze the logical correctness of the program and inspect the intermediate outputs, as well as allowing users to understand where the program fails and how to minimally tweak the instructions in order to improve the results.

The framework is evaluated on a set of four tasks:
Compositional Visual Question Answering - “Is the small truck to the left or to the right of the people that are wearing helmets?”
Zero-Shot Reasoning on Image Pairs - “Which landmark did we visit, the day after we saw the Eiffel Tower?”
Factual Knowledge Object Tagging - “List the main characters on the TV show Big Bang Theory separated by commas.”
Image Editing with Natural Language - ”Hide the face of Daniel Craig with :p” (de-identification or privacy preservation), ”Create a color pop of Daniel Craig and blur the background” (object highlighting), ”Replace Barack Obama with Barack Obama wearing sunglasses” (object replacement)

VISPROG is a powerful framework that uses the in-context learning ability of LLM to take natural language instructions and generate visual programs for complex compositional visual tasks.
Conclusion
Those simple approaches based on reasoning, requiring no further training and making use of GPT-3, achieve state-of-the-art results across various complex visual tasks, and show great promise for the future of visual programming in the field of machine learning.
References
[1] https://www.autoblocks.ai/glossary/reasoning-system, last accessed 23.10.2023
[2] D. Surís, S. Menon and C. Vondrick, “ViperGPT: Visual Inference via Python Execution
for Reasoning”, 2023 Proceedings of the IEEE/CVF International Conference on Computer
Vision (ICCV), 2023
[3] T. Gupta and A. Kembhavi, "Visual Programming: Compositional visual reasoning
without training," 2023 IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPR), Vancouver, BC, Canada, 2023






